Kerberos安全认证 |
您所在的位置:网站首页 › hdfs shell命令试题 › Kerberos安全认证 |
Kerberos安全认证
|
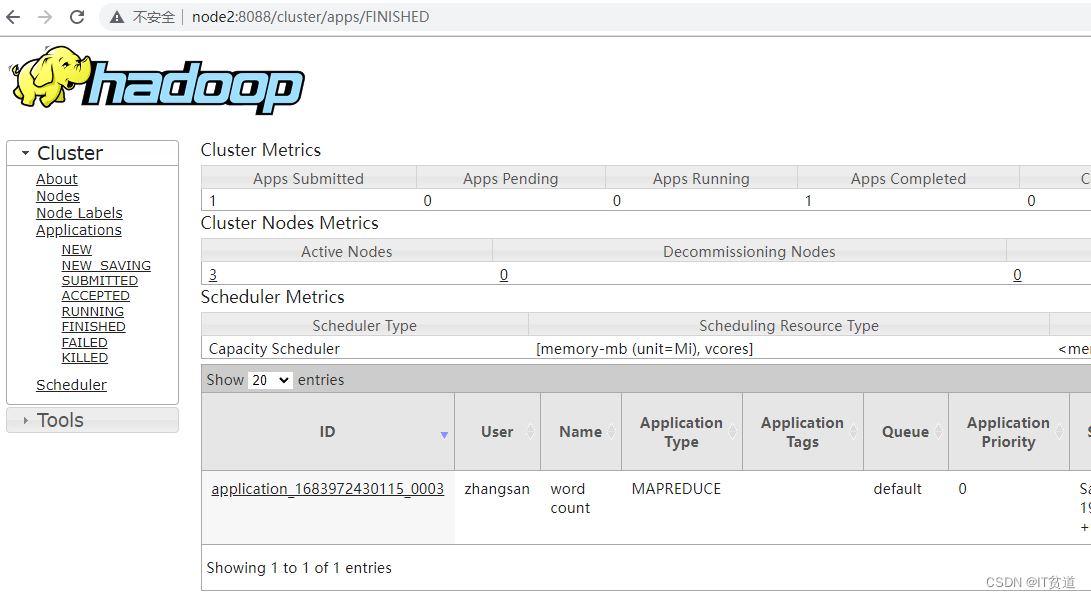
目录 1. Shell访问HDFS 2. Windows访问Kerberos认证HDFS 3.代码访问Kerberos认证的HDFS 技术连载系列,前面内容请参考前面连载8内容:Kerberos安全认证-连载8-Hadoop Kerberos安全配置_IT贫道的博客-CSDN博客 1. Shell访问HDFS这里以普通用户访问Kerberos安全认证的HDFS为例来演示普通用户访问HDFS及提交MR任务。 1) 创建zhangsan用户及设置组 在node1~node5所有节点创建zhangsan普通用户并设置密码,将zhangsan加入到hadoop组。 #node1~node5所有节点执行,设置用户密码为123456 useradd zhangsan -g hadoop passwd zhangsan目前登录zhangsan用户后,没有权限操作HDFS。 2) 创建用户主体 在node1节点上创建执行如下命令,创建用户主体。 #node1 kerberos服务端执行 [root@node1 ~]# kadmin.local -q"addprinc -pw 123456 zhangsan"3) 操作HDFS 可以在node1~node5任意节点认证zhangsan用户主体,这里选择在node5节点认证,并操作HDFS。 #在node1~node5任意节点认证zhangsan用户主体,这里选择在node5节点认证。 [root@node5 ~]# su zhangsan [zhangsan@node5 ~]$ [zhangsan@node5 ~]# kinit zhangsan Password for [email protected]: 123456 #查看认证的用户主体 [zhangsan@node5 ~]# klist Ticket cache: FILE:/tmp/krb5cc_0 Default principal: [email protected] #在HDFS中创建目录 [zhangsan@node5 ~]# hdfs dfs -mkdir /input #在node5节点准备a.txt文件,内容如下: [zhangsan@node5 ~]# cat a.txt aa bb cc aa #向HDFS中上传文件 [zhangsan@node5 ~]# hdfs dfs -put a.txt /input/ [zhangsan@node5 ~]# hdfs dfs -ls /input/ Found 1 items -rw-r--r-- 3 zhangsan hadoop 12 2023-05-13 18:59 /input/a.txt4) 提交MapReduce任务 #在node5节点提交MR WordCount 程序 [zhangsan@node5 ~]# hadoop jar /software/hadoop-3.3.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /input/a.txt /output #任务执行完成后,可以查看结果 [zhangsan@node5 ~]$ hdfs dfs -cat /output/part-r-00000 aa 2 bb 1 cc 1也可以通过Yarn Webui查看提交的MR任务。
我们可以通过Window访问keberos安全认证的HDFS WebUI,如果Windows客户端没有进行kerberos主体认证会导致在HDFS WebUI中看不到HDFS目录,这时需要我们在Window客户端进行Kerberos主体认证,在Window中进行Kerberos认证时可以使用Kerberos官方提供的认证工具,该下载地址:MIT Kerberos Distribution Page
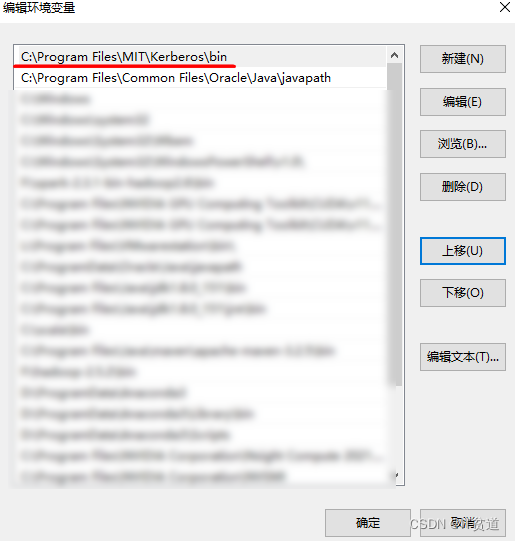
以上msi文件也可以在资料中获取,名为”kfw-4.1-amd64.msi”,下载完成该keberos客户端后双击进行安装即可。 当Window kerberos客户端工具安装完成后,需要按照如下步骤进行配置才可以正确的进行Window 客户端kerberos主体认证。 1) 配置krb5.ini 当keberos客户端安装完成后自动会在C:\ProgramData\MIT\Kerberos5路径中创建krb5.ini配置文件,我们需要配置该文件指定Kerberos服务节点及域信息,配置如下,该文件配置可以参考Kerberos服务端/etc/krb5.conf文件。 2) 调整path环境变量 Kerberos客户端工具安装完成后会自动在Window环境变量path中加入“C:\Program Files\MIT\Kerberos\bin”,默认放在最后,当我们在window中进行Kerberos主体认证时需要输入kinit命令,该命令会和JDK中的kinit命令冲突,导致无法在CMD窗口内进行kinit认证,所以这里需要调整该条信息为path中的第一条,如下图示例:
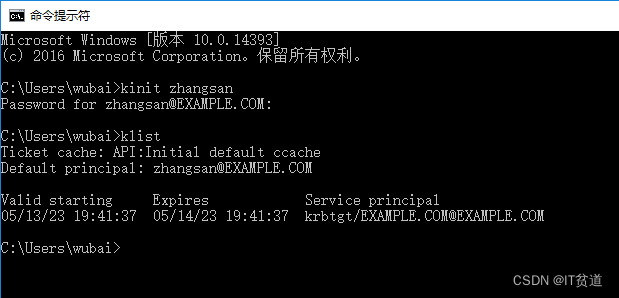
3) cmd进行Kerberos主体认证 在window中打开cmd,进行kerberos主体认证,如下图:
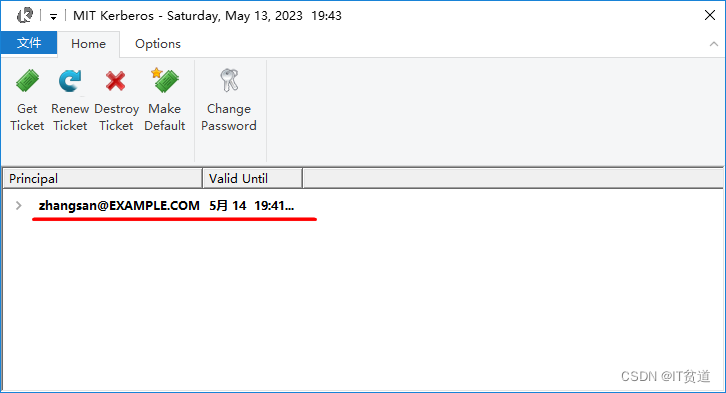
经过以上认证,可以打开Kerberos客户端工具可以看到认证信息:
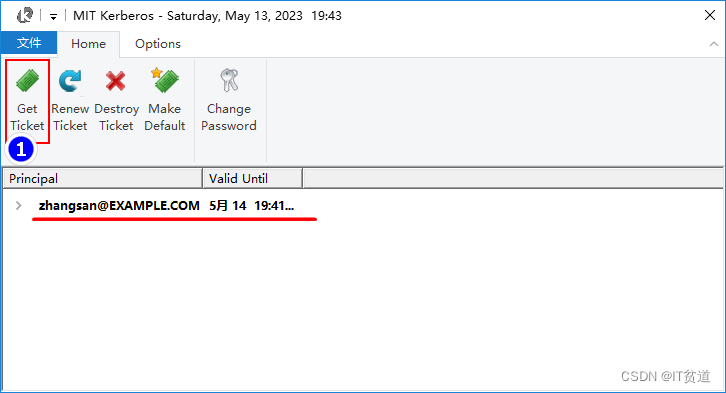
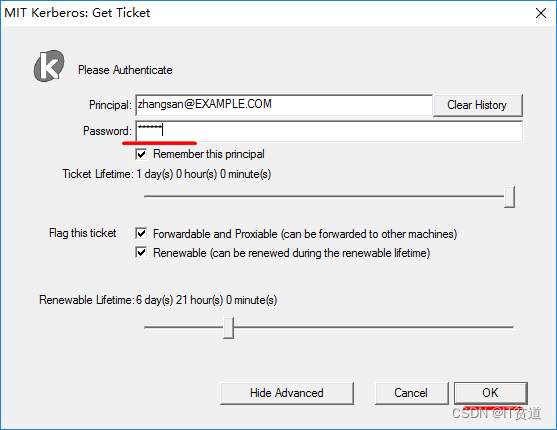
实际上我们也可以不在cmd中认证Kerberos主体,可以直接通过Kerberos客户端工具进行认证。操作如下:
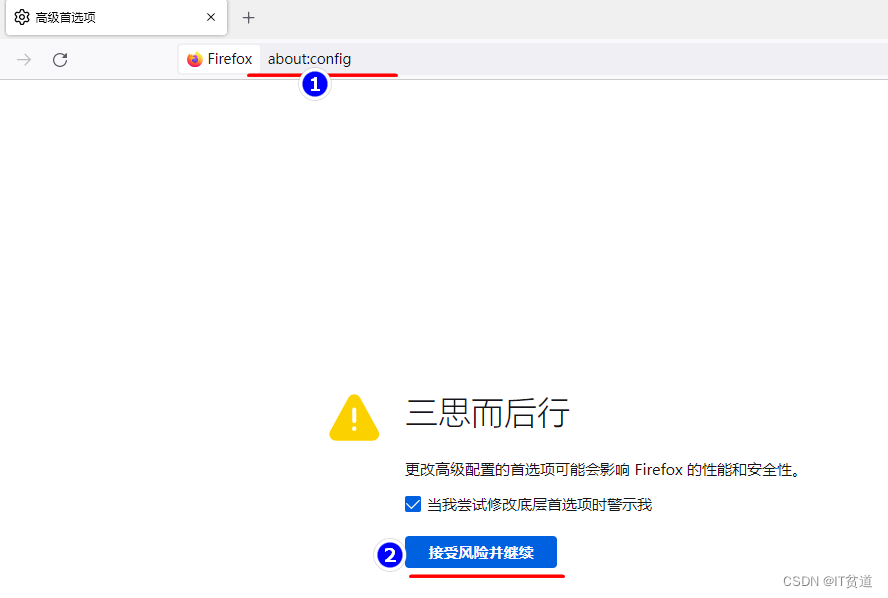
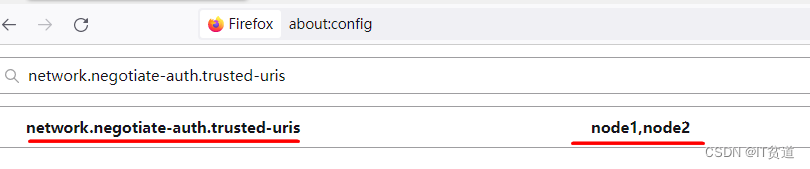
4) 配置浏览器访问HDFS WebUI 通过浏览器访问Kerberos认证的HDFS时需要对浏览器进行一些设置以支持Kerberos,目前支持较好的浏览器只有火狐。下面在火狐中进行设置以访问HDFS WebUI。 在火狐浏览器中输入“about:config”进入高级设置: 搜索“network.negotiate-auth.trusted-uris”并设置为HDFS NameNode节点,多个节点之间使用逗号分割,如下:
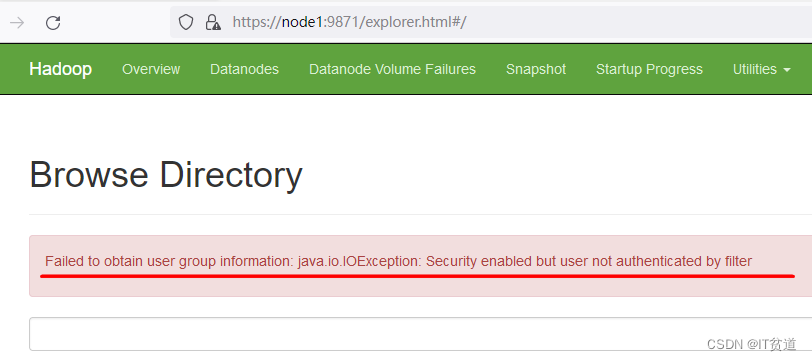
设置完成后重启火狐浏览器进行HDFS访问即可。 注意:目前在Hadoop3.3.x版本后,通过浏览器访问Kerberos认证的HDFS服务,会出现“Failed to obtain user group information: java.io.IOException: Security enabled but user not authenticated by filter”错误,如下:
该错误目前是一个bug,出现于Hadoop3.1.x版本后,详细信息参考:https://issues.apache.org/jira/browse/HDFS-16441 3.代码访问Kerberos认证的HDFSHadoop通过Kerberos认证后,在本地IDEA中访问HDFS中的数据可以通过Keytab来进行认证,这里在本地Idea中操作HDFS以zhangsan用户为例,配置如下: 1) 准备krb5.conf文件 将node1 kerberos服务端/etc/krb5.conf文件存放在IDEA项目中的resources资源目录中或者本地Window固定的某个目录中,用于编写代码时指定访问Kerberos的Realm。 2) 生成用户keytab文件 在kerberos服务端node1节点上,执行如下命令,对zhangsan用户主体生成keytab密钥文件。 #在node1 kerberos服务端执行 [root@node1 ~]# kadmin.local -q "ktadd -norandkey -kt /root/zhangsan.keytab [email protected]"以上命令执行之后,在/root目录下会生成zhangsan.keytab文件,将该文件复制到IDEA项目中的resources资源目录中或者本地window固定的某个目录中,该文件用于编写代码时认证kerberos。 3) 准备访问HDFS需要的资源文件 将HDFS中的core-site.xml 、hdfs-site.xml 、yarn-site.xml文件上传到项目resources资源目录中。 4) 编写代码操作HDFS 编写Java代码操作Kerberos认证的HDFS集群: /** * 操作Kerberos认证的HDFS文件系统 */ public class OperateAuthHDFS { public static FileSystem fs = null; public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException { final Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://mycluster"); System.setProperty("java.security.krb5.conf", "D:\\idea_space\\KerberosAuth\\KerberosAuthHDFS\\src\\main\\resources\\krb5.conf"); UserGroupInformation.loginUserFromKeytab("zhangsan", "D:\\idea_space\\KerberosAuth\\KerberosAuthHDFS\\src\\main\\resources\\zhangsan.keytab"); UserGroupInformation ugi = UserGroupInformation.getLoginUser(); fs = ugi.doAs(new PrivilegedExceptionAction() { @Override public FileSystem run() throws Exception { return FileSystem.get(conf); } }); //查看HDFS路径文件 listHDFSPathDir("/"); System.out.println("====================================="); //创建目录 mkdirOnHDFS("/kerberos_test"); System.out.println("====================================="); //向HDFS 中写入数据 writeFileToHDFS("D:\\idea_space\\KerberosAuth\\KerberosAuthHDFS\\data\\test.txt","/kerberos_test/test.txt"); System.out.println("====================================="); //读取HDFS中的数据 readFileFromHDFS("/kerberos_test/test.txt"); System.out.println("====================================="); //删除HDFS中的目录或者文件 deleteFileOrDirFromHDFS("/kerberos_test"); System.out.println("====================================="); //关闭fs对象 fs.close(); } private static void listHDFSPathDir(String hdfsPath) throws IOException { FileStatus[] fileStatuses = fs.listStatus(new Path(hdfsPath)); for (FileStatus fileStatus : fileStatuses) { System.out.println(fileStatus.getPath()); } } private static void mkdirOnHDFS(String dirpath) throws IOException { Path path = new Path(dirpath); //判断目录是否存在 if(fs.exists(path)) { System.out.println("目录" + dirpath + "已经存在"); return; } //创建HDFS目录 boolean result = fs.mkdirs(path); if(result) { System.out.println("创建目录" + dirpath + "成功"); } else { System.out.println("创建目录" + dirpath + "失败"); } } private static void writeFileToHDFS(String localFilePath, String hdfsFilePath) throws IOException { //判断HDFS文件是否存在,存在则删除 Path hdfsPath = new Path(hdfsFilePath); if(fs.exists(hdfsPath)) { fs.delete(hdfsPath, true); } //创建HDFS文件路径 Path path = new Path(hdfsFilePath); FSDataOutputStream out = fs.create(path); //读取本地文件写入HDFS路径中 FileReader fr = new FileReader(localFilePath); BufferedReader br = new BufferedReader(fr); String newLine = ""; while ((newLine = br.readLine()) != null) { out.write(newLine.getBytes()); out.write("\n".getBytes()); } //关闭流对象 out.close(); br.close(); fr.close(); System.out.println("本地文件 ./data/test.txt 写入了HDFS中的"+path.toString()+"文件中"); } private static void readFileFromHDFS(String hdfsFilePath) throws IOException { //读取HDFS文件 Path path= new Path(hdfsFilePath); FSDataInputStream in = fs.open(path); BufferedReader br = new BufferedReader(new InputStreamReader(in)); String newLine = ""; while((newLine = br.readLine()) != null) { System.out.println(newLine); } //关闭流对象 br.close(); in.close(); } private static void deleteFileOrDirFromHDFS(String hdfsFileOrDirPath) throws IOException { //判断HDFS目录或者文件是否存在 Path path = new Path(hdfsFileOrDirPath); if(!fs.exists(path)) { System.out.println("HDFS目录或者文件不存在"); return; } //第二个参数表示是否递归删除 boolean result = fs.delete(path, true); if(result){ System.out.println("HDFS目录或者文件 "+path+" 删除成功"); } else { System.out.println("HDFS目录或者文件 "+path+" 删除成功"); } } }注意,以上代码maven引入依赖如下: org.apache.hadoop hadoop-client 3.3.45)Spark代码操作HDFS 向HDFS中上传wc.txt文件,在node5节点中准备wc.txt文件,文件内容如下: hello zs hello ls hello ww上传操作如下: [root@node5 ~]# su zhangsan [zhangsan@node5 root]$ cd [zhangsan@node5 ~]$ hdfs dfs -put ./wc.txt /编写Spark代码操作Kerberos认证的HDFS集群: /** * Spark操作Kerberos认证的HDFS */ public class SparkOperateAuthHDFS { public static void main(String[] args) throws IOException { //进行kerberos认证 System.setProperty("java.security.krb5.conf", "D:\\idea_space\\KerberosAuth\\KerberosAuthHDFS\\src\\main\\resources\\krb5.conf"); String principal = "[email protected]"; String keytabPath = "D:\\idea_space\\KerberosAuth\\KerberosAuthHDFS\\src\\main\\resources\\zhangsan.keytab"; UserGroupInformation.loginUserFromKeytab(principal, keytabPath); SparkConf conf = new SparkConf(); conf.setMaster("local"); conf.setAppName("SparkOperateAuthHDFS"); JavaSparkContext jsc = new JavaSparkContext(conf); jsc.textFile("hdfs://mycluster/wc.txt").foreach(line -> System.out.println(line)); jsc.stop(); } }注意,以上代码maven引入依赖如下,需要提前在HDFS中上传wc.txt文件。 org.apache.spark spark-core_2.12 3.4.06) Flink代码操作HDFS /** * Flink 读取Kerberos认证的HDFS文件 */ public class FlinkOperateAuthHDFS { public static void main(String[] args) throws Exception { //进行kerberos认证 System.setProperty("java.security.krb5.conf", "D:\\idea_space\\KerberosAuth\\KerberosAuthHDFS\\src\\main\\resources\\krb5.conf"); String principal = "[email protected]"; String keytabPath = "D:\\idea_space\\KerberosAuth\\KerberosAuthHDFS\\src\\main\\resources\\zhangsan.keytab"; UserGroupInformation.loginUserFromKeytab(principal, keytabPath); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); FileSource fileSource = FileSource.forRecordStreamFormat( new TextLineInputFormat(), new Path("hdfs://mycluster/wc.txt")).build(); DataStreamSource dataStream = env.fromSource(fileSource, WatermarkStrategy.noWatermarks(), "file-source"); dataStream.print(); env.execute(); } }以上代码需要导入以下maven依赖: org.apache.flink flink-clients 1.16.0 org.apache.flink flink-connector-files 1.16.0欢迎点赞、评论、收藏,关注IT贫道,获取IT技术知识! |
 搜索“network.auth.use-sspi”并设置为false,如下:
搜索“network.auth.use-sspi”并设置为false,如下: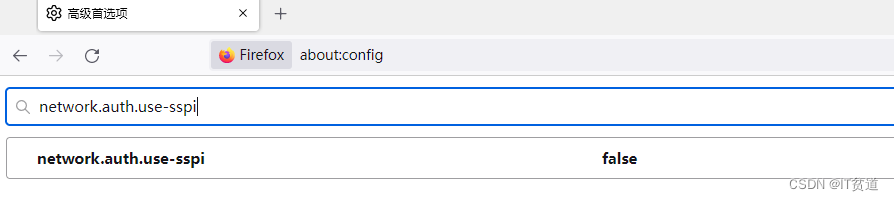
【本文地址】